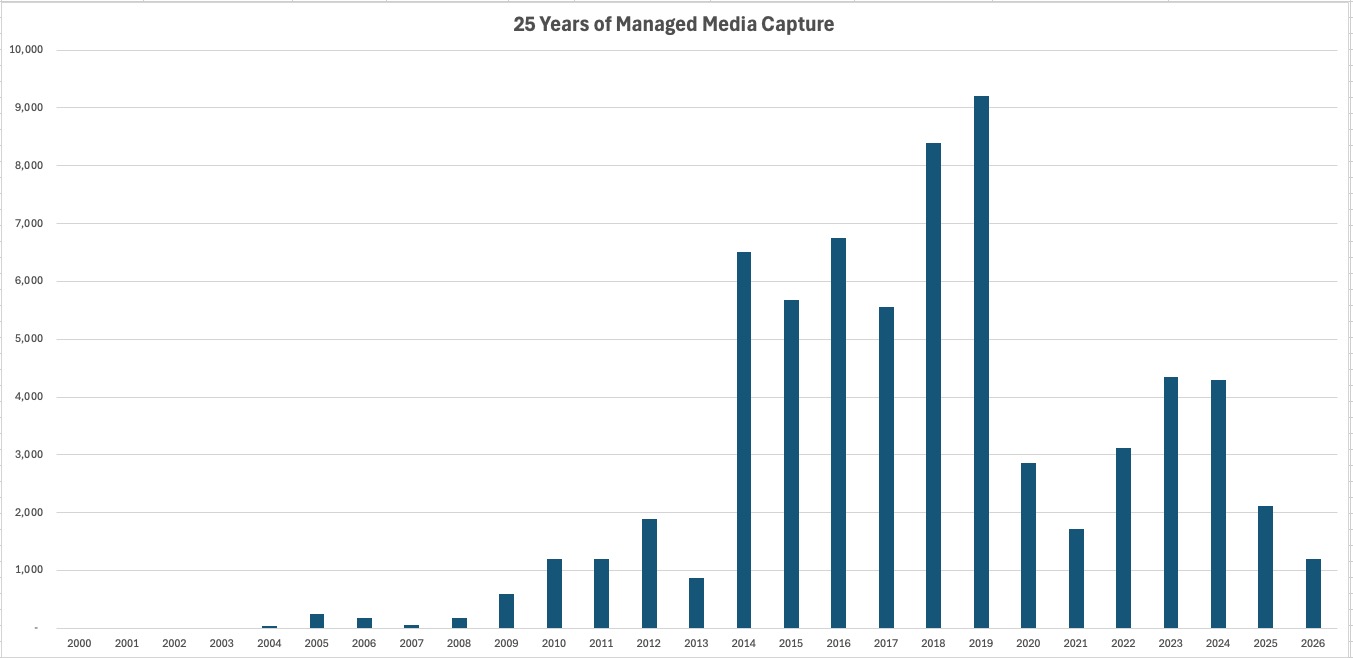
Executive summary
What begins as backup can become fragmentation
This study examines what happens when photo libraries are copied, backed up, migrated, and preserved over many years. What begins as a simple protection strategy can gradually create multiple library copies, fragmented archives, duplicated assets, incomplete metadata, and accumulated structural drift beneath the browsing layer.
Research topic: deterministic normalization in managed libraries. The central finding is simple: when organization begins at file level, archives become structurally simpler, operationally more predictable, and progressively easier to normalize.
Why managed libraries still drift
Modern photo libraries feel organized because albums, dates, locations, faces, and search create a polished browsing experience. For everyday use, that is enough. But browsing structure is not the same as archival structure.
Over time, libraries are copied, migrated, backed up, exported, consolidated, and replaced across devices. These normal lifecycle events create silent structural layers underneath the catalog.
Structural drift
Hidden duplication
Even curated libraries carried silent duplication created by replication, migration, backup, and export workflows.
Metadata quality
High confidence
Managed libraries remained overwhelmingly metadata-rich, with only 3.8% of files lacking GPS data.
Operational locality
Structure creates efficiency
Chronological continuity and metadata consistency made the workload naturally more predictable.
Normalize before you catalog
Traditional workflows begin inside software: files are imported, metadata is indexed, albums are created, and organization becomes part of the application experience.
That works until archives become large, duplicated, fragmented, or historically layered. At that point, the catalog begins carrying structural complexity that was never resolved at file level.
Normalization establishes structural truth before cataloging begins.
- when the file was captured
- where it was captured, when location metadata exists
- what type of media it is
- whether it is unique or duplicated
- whether its metadata is complete or incomplete
- how it should be structurally placed inside the archive
Catalogs organize experiences. File-level normalization organizes archives.
Key findings
What the archive revealed
Finding 1
Hidden duplication is significant
The managed-library segment showed a 29.6% duplicate ratio, even though the libraries remained usable and visually organized inside catalog software.
Finding 2
Metadata quality is high
Only 3.8% of files lacked GPS information, creating strong normalization confidence and cleaner deterministic outcomes.
Finding 3
Knowledge accumulation dominates
Location resolution became reuse-driven over time, with 73.4% accumulated reuse across the study.
Finding 4
Cost converges
Despite mixed workload composition, normalization stabilized around a narrow operating regime of approximately 1.05 seconds per file.
Finding 5
Structure creates efficiency
Well-structured archives normalized more predictably without changing the normalization logic itself.
Core result
Local variability. Global predictability.
Individual segments varied, but cumulative behavior became operationally stable as archive knowledge grew.
Archives are historical systems
Large archives are not static datasets. They are historical systems shaped by device replacement, library migration, backup consolidation, exports, and ecosystem changes.
Growth is not purely additive. Personal archives often expand in structural jumps, and those transitions frequently introduce silent duplication layers that remain hidden inside otherwise well-managed libraries.
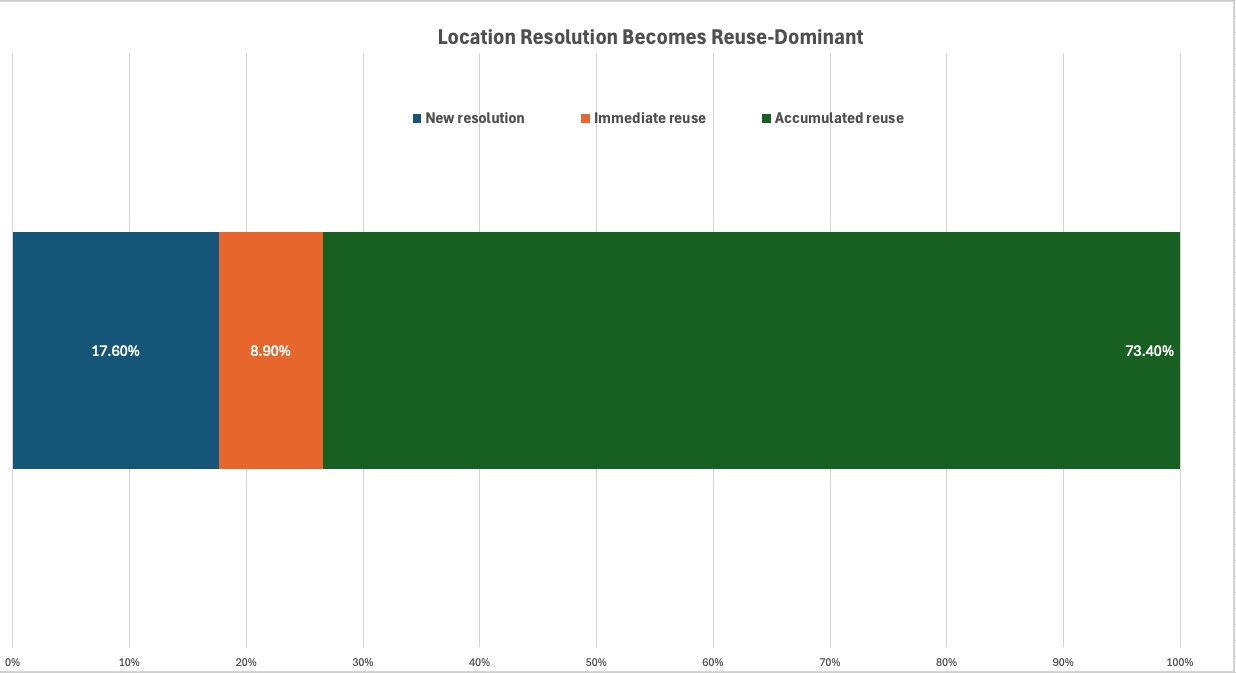
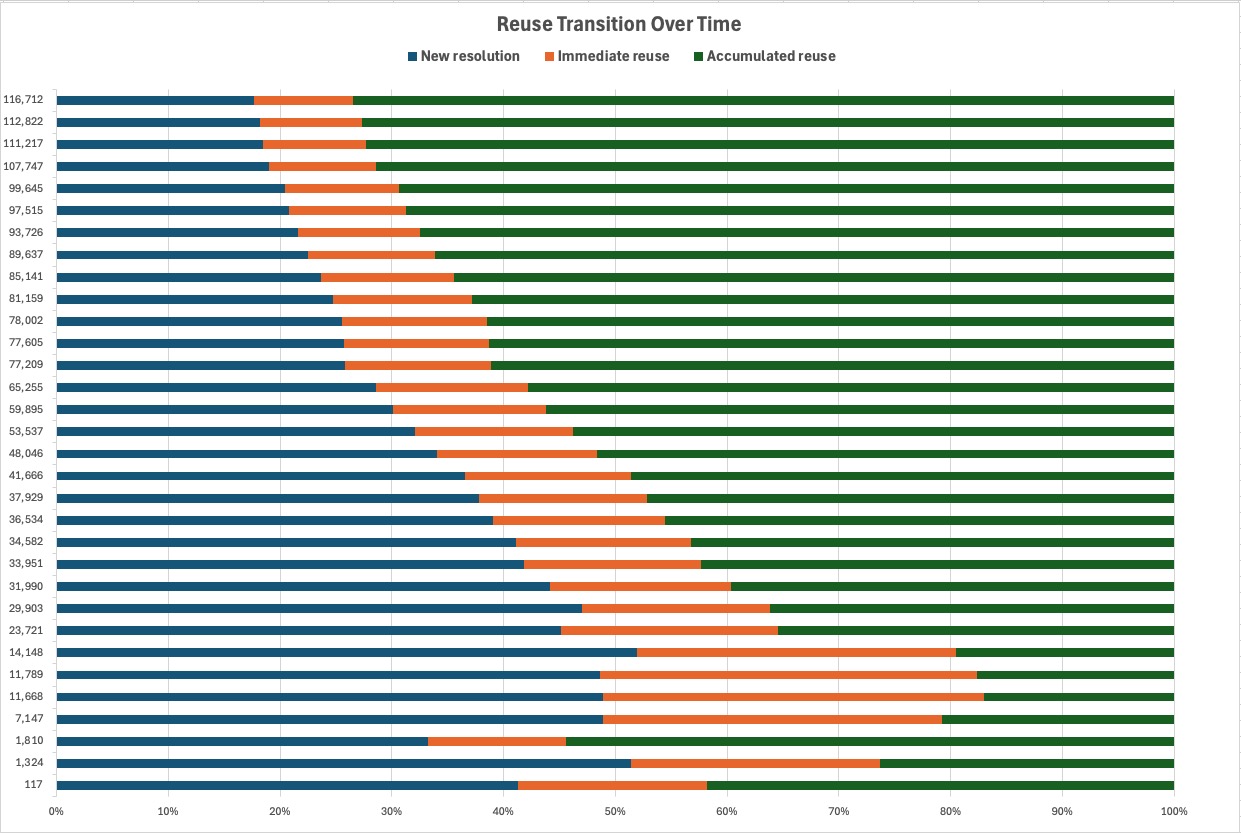
Normalization becomes knowledge-driven
At the beginning of a normalization workflow, new location resolution may still be meaningful. But as archive knowledge accumulates, reuse becomes the dominant operational pattern.
In this study, accumulated reuse reached 73.4%. That matters because normalization progressively shifts from dependency-driven execution toward knowledge-driven execution.
Full paper
Download the complete Study #1 PDF
The HTML version summarizes the study for the web. The full PDF keeps the complete paper structure, detailed narrative, and original benchmark framing.
Operational pattern
Warm-up → Adaptation → Steady regime
Normalization did not behave as a single flat throughput number. It moved through recognizable phases: initial discovery and resolution, progressive reuse, and a steadier operating regime as the archive became increasingly understood.
Phase 1
Warm-up
The system resolves new locations, discovers duplicate patterns, and begins accumulating operational knowledge.
Phase 2
Adaptation
Reuse increases, repeated geographic contexts become cheaper, and operating cost begins to narrow.
Phase 3
Steady regime
The cumulative profile stabilizes as normalization becomes increasingly driven by accumulated archive knowledge.
What this changes
File-level normalization is not simply a cleanup step. It changes what an archive becomes.
- Cleaner archives become portable archives. Structure remains readable outside any one catalog.
- Duplicate propagation stops. Structural duplication becomes visible instead of silently multiplying.
- Uncertainty remains preserved. Incomplete metadata remains explicit and reviewable.
- Local-first processing preserves ownership. The archive does not need to be uploaded to become organized.
- Normalization becomes the structural layer beneath catalogs. Catalogs organize experience; normalization preserves archive truth.
From principle to practice
The ideas in this study did not begin as theory. They emerged from practical normalization work on a large, real-world archive. From that work came a practical model: originals remain preserved, duplicates stop propagating, unresolved media remains visible, archives remain portable, processing remains local, and organization becomes deterministic.
MediaOrganizer was developed around those principles in practice — not as a catalog replacement, but as the structural layer beneath future organization.
Step Zero of media organization. Everything else can come after.
Continue reading
The benchmark series
Current study
Study #1 — Years of Photo Library Copies and Backups: The Hidden Consequences
Structure improves normalization efficiency.
Next
Study #2 — What Years of Media Imports and Migrations Really Look Like
Fragmented folders reveal the operational cost of losing structure.
Model
Study #3 — From Chaos in Photo Libraries and Media Folders to an Organized Archive
A consolidated model for long-lived media archives.
Organizing Real Archives
These structural problems do not appear overnight. They accumulate through years of copying libraries, creating backups, importing from devices, and moving media between systems.
MediaOrganizer helps organize and maintain photo archives using metadata, capture time, location information, duplicate isolation, and consistent file-level rules.
Whether the goal is preparing for Lightroom, consolidating Apple Photos libraries, or simply maintaining a long-term archive, the objective is the same: preserve structure before complexity accumulates.
Learn more about MediaOrganizer →
![]()