Executive summary
Imports and migrations leave structural traces
Every import, export, migration, backup, recovery workflow, and device replacement leaves traces behind. Over time, those traces accumulate into fragmented folders, duplicated storage layers, incomplete metadata, NoGPS-heavy workloads, video-heavy segments, and deep directory trees that are difficult to understand and trust.
Research topic: normalization under structural entropy. The strongest result was not raw throughput. It was deterministic convergence under operational stress: even when archive structure became fragmented, heterogeneous, and difficult, normalization behavior remained measurable, explainable, and globally predictable.
From managed libraries to unmanaged archives
Study #1 showed how structure improves normalization behavior. Study #2 moves into the opposite environment: unmanaged archives accumulated directly at filesystem level.
This distinction matters because libraries and folders do not behave the same way structurally. Managed libraries preserve locality, metadata continuity, and predictable behavior. Folder archives accumulate entropy progressively through years of ordinary use.
Managed libraries
Structure preserved
- High metadata consistency
- Strong geolocation continuity
- Natural chronological locality
- Logical duplicate handling
- Cache-friendly workload behavior
Unmanaged archives
Structure fragmented
- Deep directory trees
- Mixed provenance and historical layers
- Recovered and metadata-degraded media
- Physical duplicate propagation
- Randomized I/O access patterns
Structural entropy at scale
Large folder-based archives do not become complex all at once. They accumulate entropy gradually through migrations, backups, exports, synchronization workflows, recovery processes, device replacement cycles, and years of normal storage growth.
The filesystem becomes a visible record of operational history: duplicated folders, nested exports, recovered media, temporary copies, fragmented chronology, inconsistent naming, and metadata degradation.
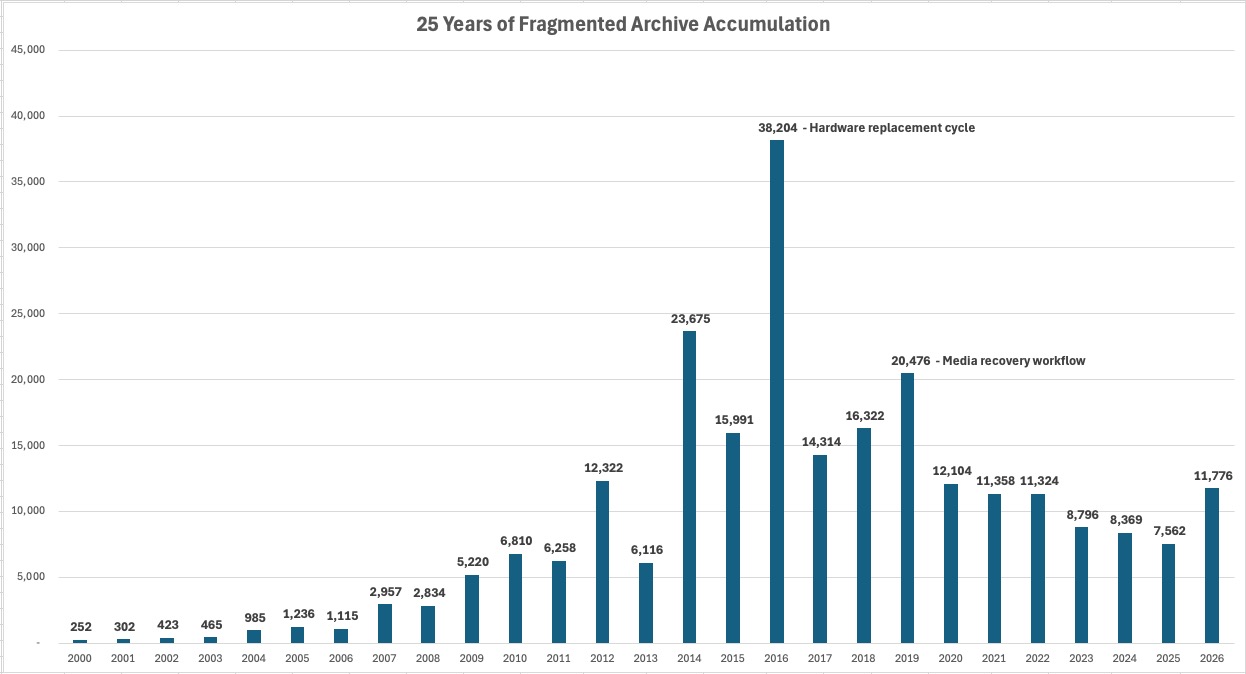
Key findings
What fragmented archives revealed
Finding 1
Structural entropy dominates cost
Processing behavior varied more with workload composition than with dataset size itself. NoGPS density, duplicate movement, directory locality, file size, and video concentration became dominant variables.
Finding 2
Normalization remained stable
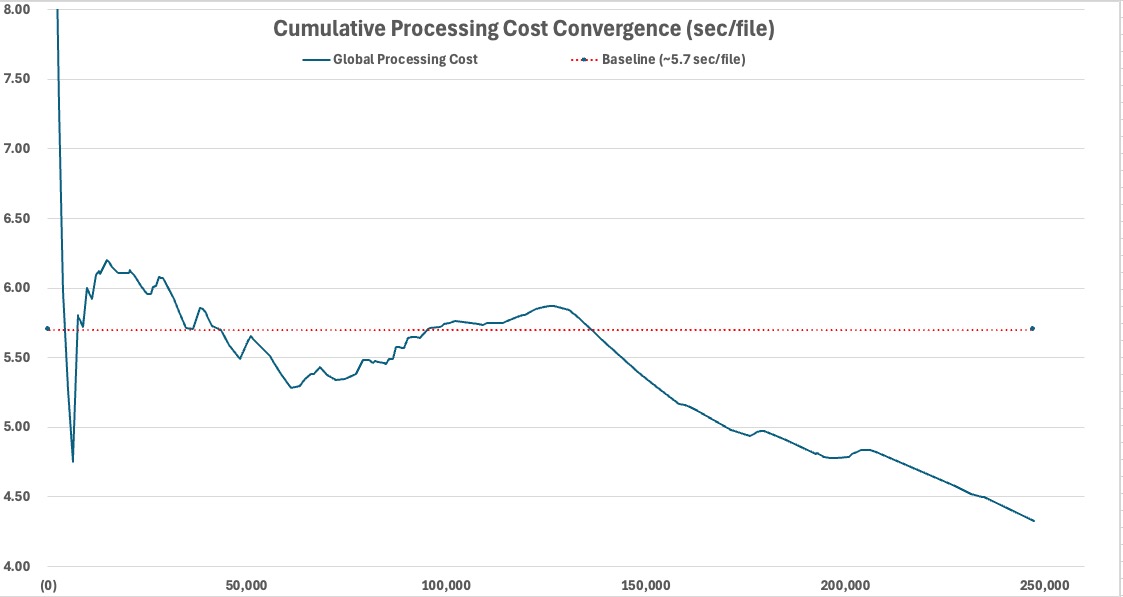
Despite heterogeneous workload conditions and multi-day execution, global operating cost converged toward approximately 4.33 seconds per file.
Finding 3
Duplicates became physical I/O
Folder normalization physically handled 85,630 duplicated files, transforming duplicate management into a sustained storage and write-amplification workload.
Finding 4
Metadata availability reshaped throughput
NoGPS-heavy segments often reduced unit cost by minimizing geolocation-resolution work, showing that location resolution was not the dominant bottleneck under fragmented workloads.
Finding 5
Execution state mattered
Long-running I/O-bound execution proved sensitive to operating system interaction state, including idle and screensaver conditions.
Core result
Operational variability remained explainable
The archive did not behave randomly. It behaved as a sequence of observable operational states.
Operational conditions
This was not a synthetic benchmark. The workload ran under real-world operational conditions using consumer hardware, encrypted storage, deep directory traversal, random HDD reads, SSD writes, metadata extraction, duplicate movement, and large video handling.
Machine
MacBook Pro M2 Pro
32 GB unified memory, fully local execution, no cloud upload, no distributed compute.
Source
Encrypted HDD
WD My Passport 4 TB, exposing filesystem locality and seek-heavy access patterns.
Destination
Encrypted SSD
Samsung Portable SSD T7 Shield 4 TB, receiving organized and duplicated outputs.
Operational regimes
The folder archive did not behave like a uniform dataset. It behaved like a sequence of regimes shaped by metadata density, duplicate concentration, filesystem locality, media composition, file size, and execution state.
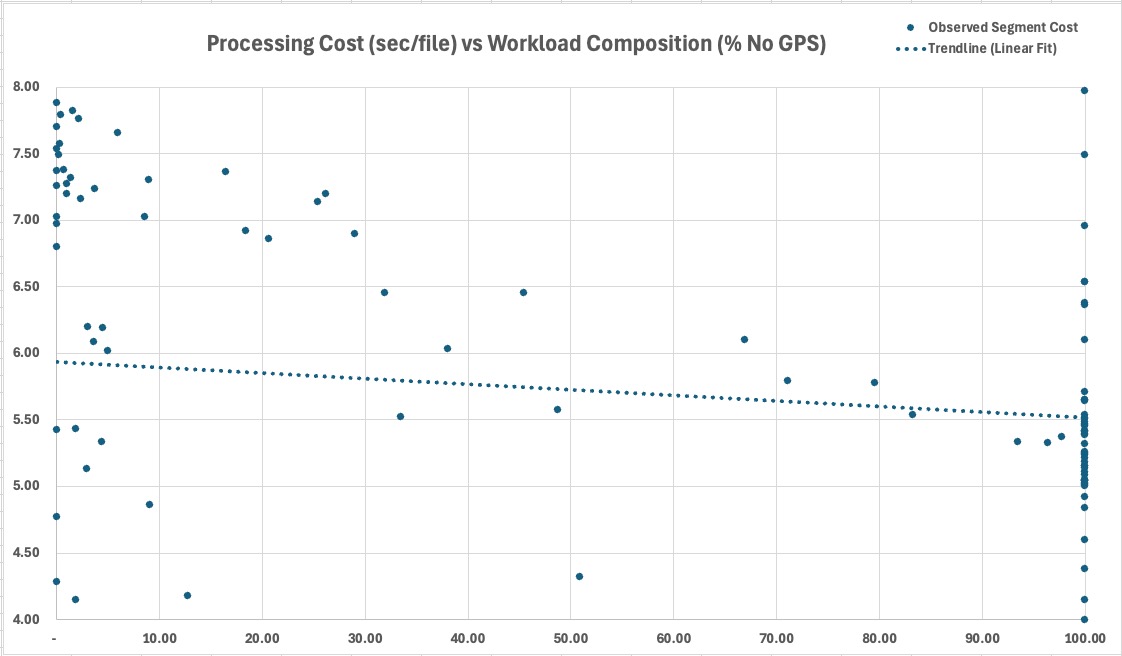
Regime
Cache-dominant
Strong location continuity and accumulated reuse reduced external dependency and stabilized cost.
Regime
NoGPS-heavy
Metadata-light segments exposed a lower cost boundary by avoiding repeated location-resolution work.
Regime
Video-heavy
Large video directories amplified sustained I/O cost through prolonged read/write activity.
Regime
Duplicate-heavy
Duplicate handling became physical movement, creating sustained write amplification.
Regime
Seek-bound
Fragmented traversal reduced locality and forced unstable HDD access patterns.
Regime
Execution-state
Idle and screensaver conditions materially influenced throughput during long-running I/O-bound execution.
Unexpected finding
Execution state became an operational variable
One of the most unexpected findings was that throughput depended not only on archive composition, but also on the interaction state of the operating system itself.
During long-running I/O-bound execution, segments processed under prolonged screensaver and idle-state conditions showed measurable throughput degradation despite stable workload composition and controlled power settings.
The workload remained stable. The archive composition remained stable. Only the execution state changed.
This behavior was initially difficult to explain because the benchmark itself had not changed. The same directories, storage devices, workload composition, and execution pipeline produced materially different throughput depending only on whether the system remained actively interactive or entered prolonged idle-state conditions.
What initially appeared to be random operational instability gradually revealed a repeatable execution-state regime associated with screensaver and idle-state transitions during sustained I/O-bound processing.
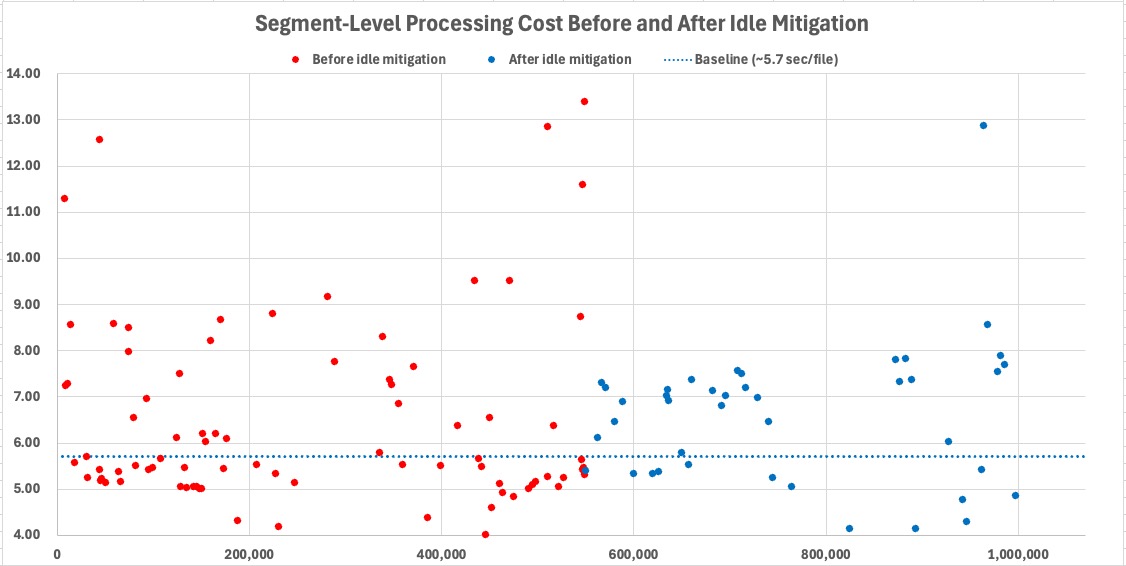
Local variability. Global predictability.
Local segments varied continuously. Some were metadata-light, some duplicate-heavy, some video-heavy, and some seek-bound. Yet cumulative operating behavior remained structurally explainable and globally stable over time.
That is the defining result of Study #2: deterministic normalization remained viable even when archive structure deteriorated.
What this changes
Study #2 changes how large-scale normalization should be understood. At scale, normalization behaves less like a simple metadata utility and more like a long-running operational system interacting with storage, filesystem structure, workload composition, and execution conditions.
- Archive quality exists on a spectrum. Managed libraries and fragmented folders are different points along the same continuum.
- Workload composition matters more than raw volume. Cost follows metadata density, locality, duplicates, video concentration, and execution state.
- Determinism survives structural entropy. Even fragmented workloads remained measurable, explainable, and predictable.
- Normalization becomes more valuable as archives degrade. Messy archives are where structural visibility matters most.
Normalization did not eliminate entropy. It made entropy operationally intelligible.
Continue reading
The benchmark series
Previous
Study #1 — Years of Photo Library Copies and Backups: The Hidden Consequences
Structured libraries reveal how metadata continuity and accumulated knowledge improve normalization efficiency.
Current study
Study #2 — What Years of Media Imports and Migrations Really Look Like
Fragmented folders reveal the operational cost of losing structure.
Model
Study #3 — From Chaos in Photo Libraries and Media Folders to an Organized Archive
A consolidated model for long-lived media archives.
Organizing Fragmented Archives
Most archives do not become fragmented because of a single mistake. Fragmentation usually appears gradually through years of imports, exports, backups, migrations, device changes, recovered files, and copied libraries.
MediaOrganizer helps organize archives before those structural problems become harder to understand and maintain, using metadata, capture time, location information, duplicate isolation, and consistent file-level rules.
Learn more about MediaOrganizer →
![]()