File-level Media Normalization: A 37,614-Photo Archive Case Study
A real-world normalization run across 311 source folders and 18 years of media, showing how a large archive can be rebuilt into a deterministic structure before any catalog or DAM.
This page documents the archive, the setup, the execution timeline and the resulting structure, as an application of file-level media normalization, showing how this method performs in practice on a large, real-world archive.
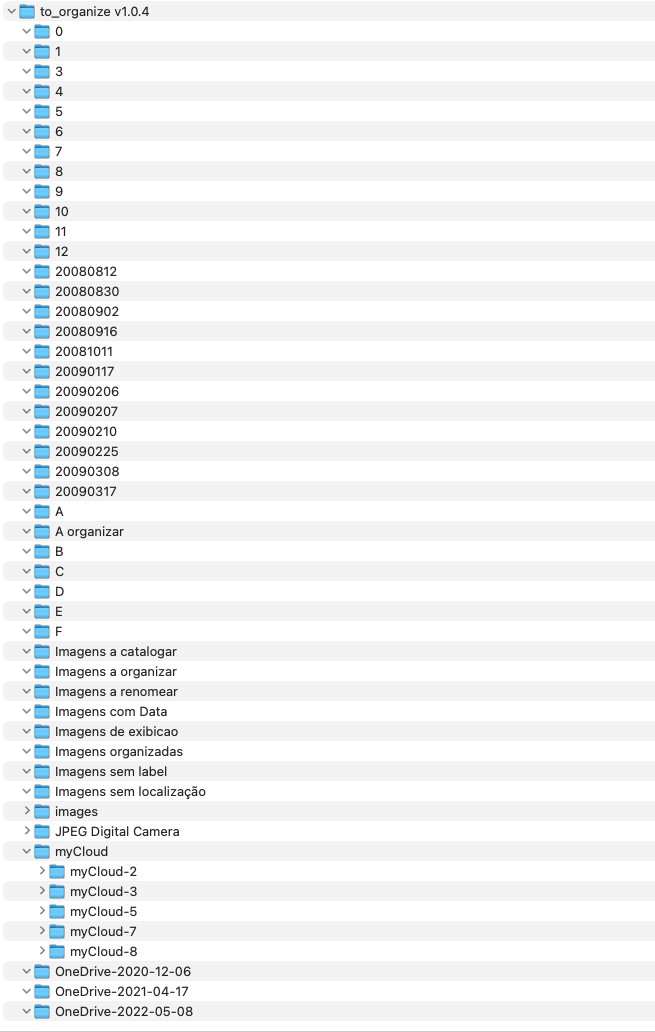
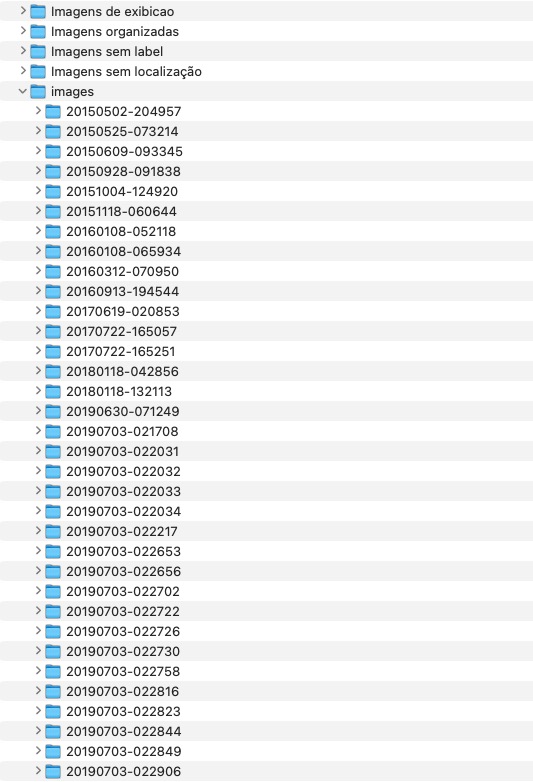
The archive before normalization
The source archive contained media accumulated over many years across disconnected folder trees, inconsistent naming conventions and mixed device origins.
In total, the dataset included:
- 37,614 media files processed
- 311 source directories
- date span from 2001 to 2019

Environment and setup
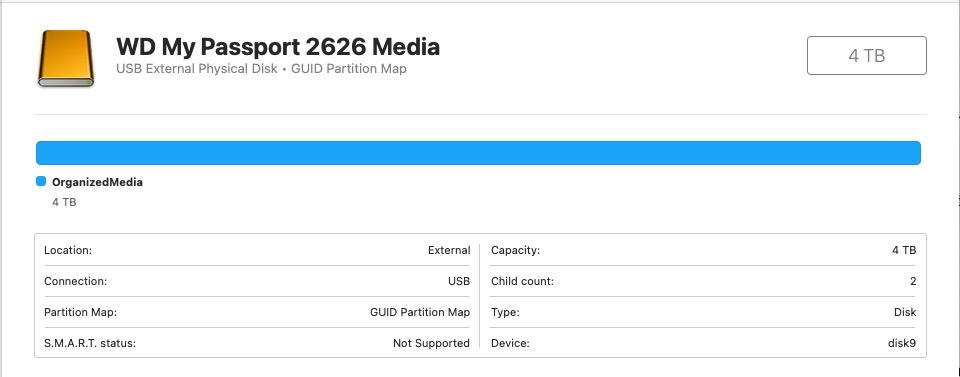
This execution was performed on a Mac-based local workflow using MediaOrganizer Studio, with the archive read from an HDD.

What normalization means here
In this workflow, normalization means rebuilding the archive according to media metadata rather than preserving inherited folder logic from old exports, copied drives or ad hoc manual structures.
Country / State / City / Year / Month / Day / Timestamp.ext
The result is a structure that is deterministic, readable and rebuildable, and that can then feed Lightroom, Apple Photos or any DAM from a much cleaner foundation.
Loading and discovery phase
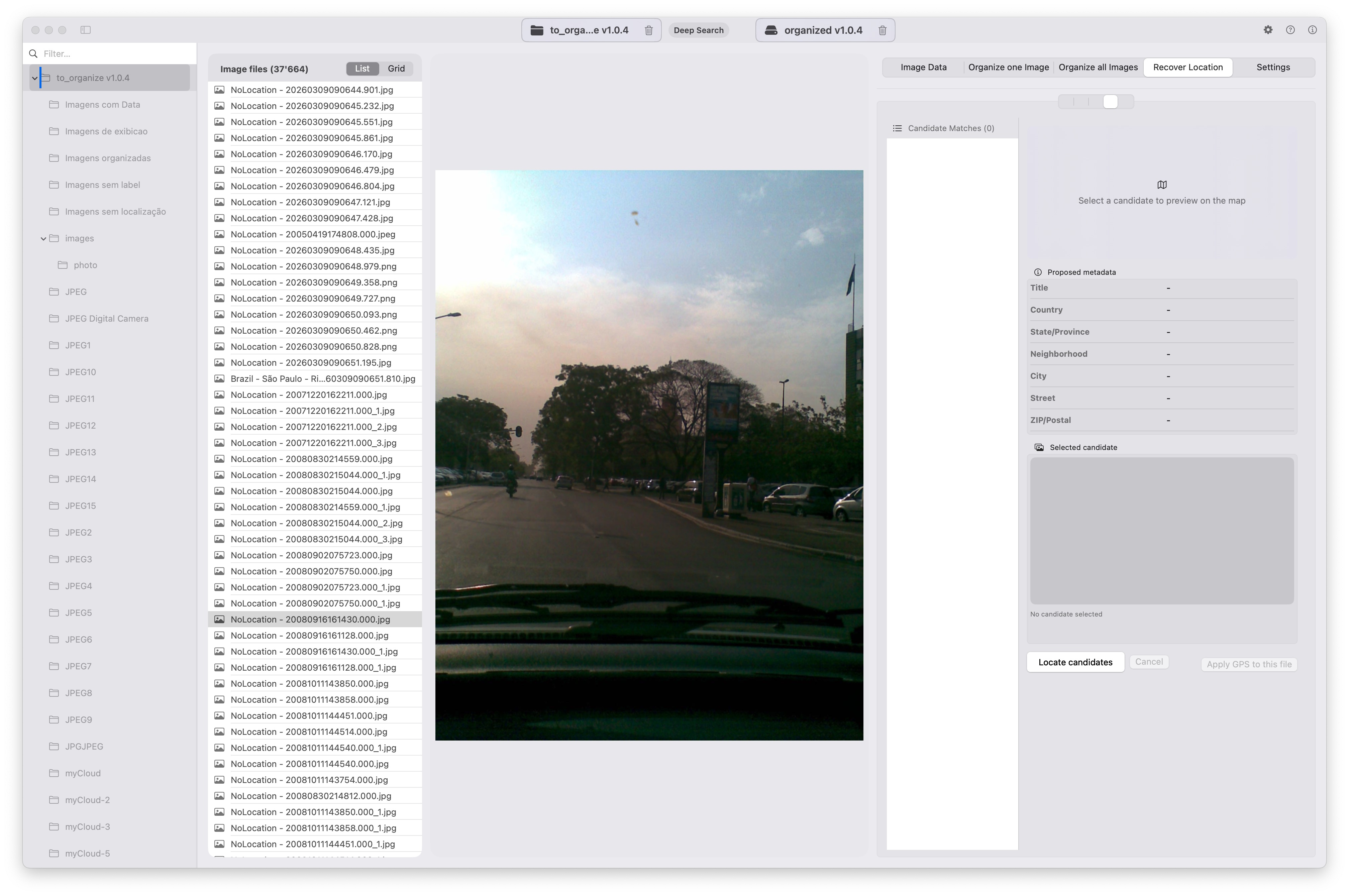
Initial indexing time for the archive was approximately 54.38 seconds.
That separation matters: discovery happens first, normalization happens second. In large archives, recursive visibility into nested folders is what makes deterministic rebuilding possible.
Normalization pipeline in execution
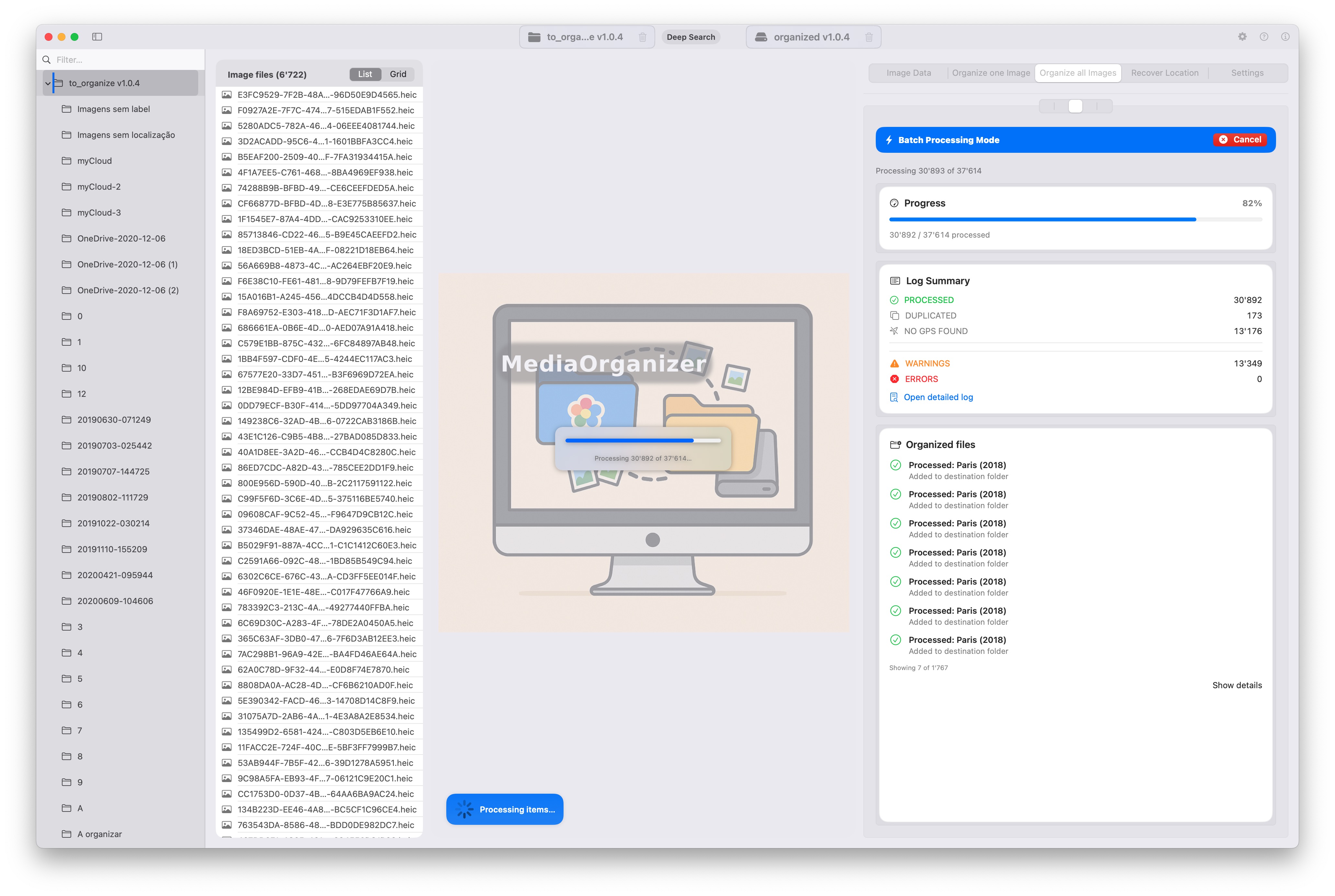
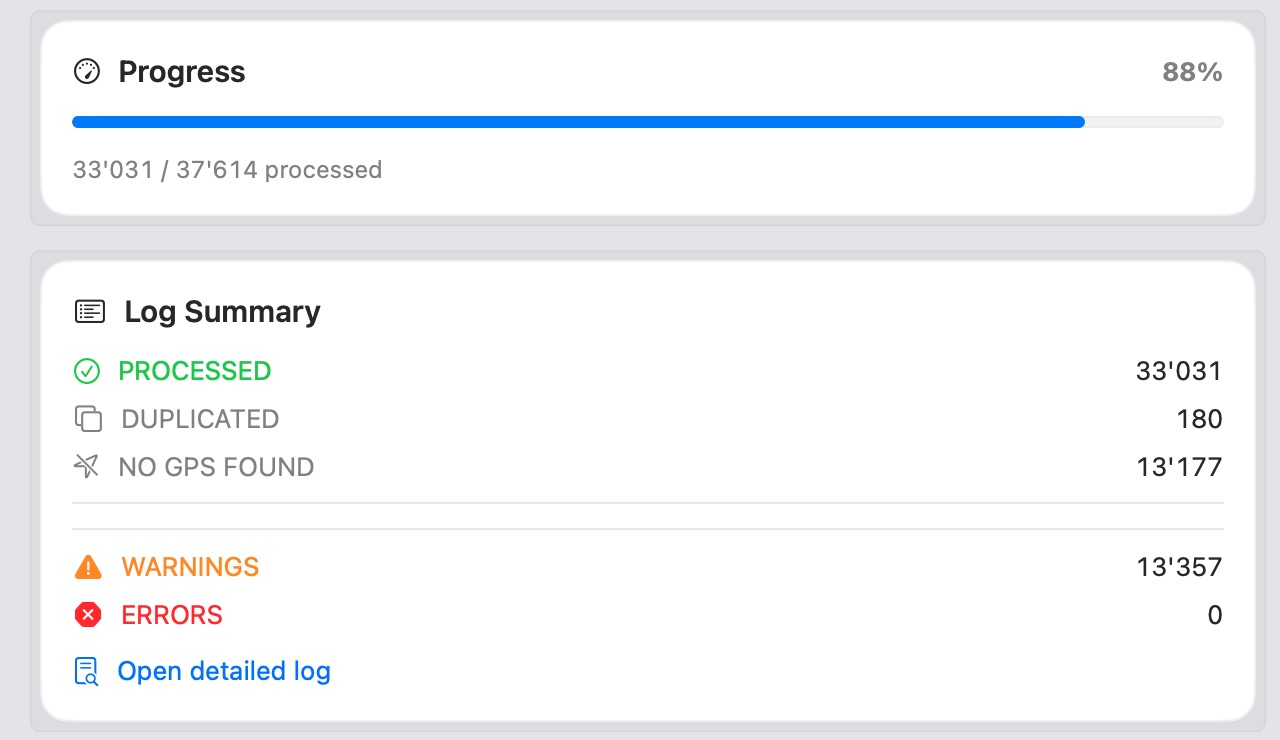
Runtime:
- Start: 11:55:16
- End: 21:03:52
- Total: approximately 9h08m
Final result
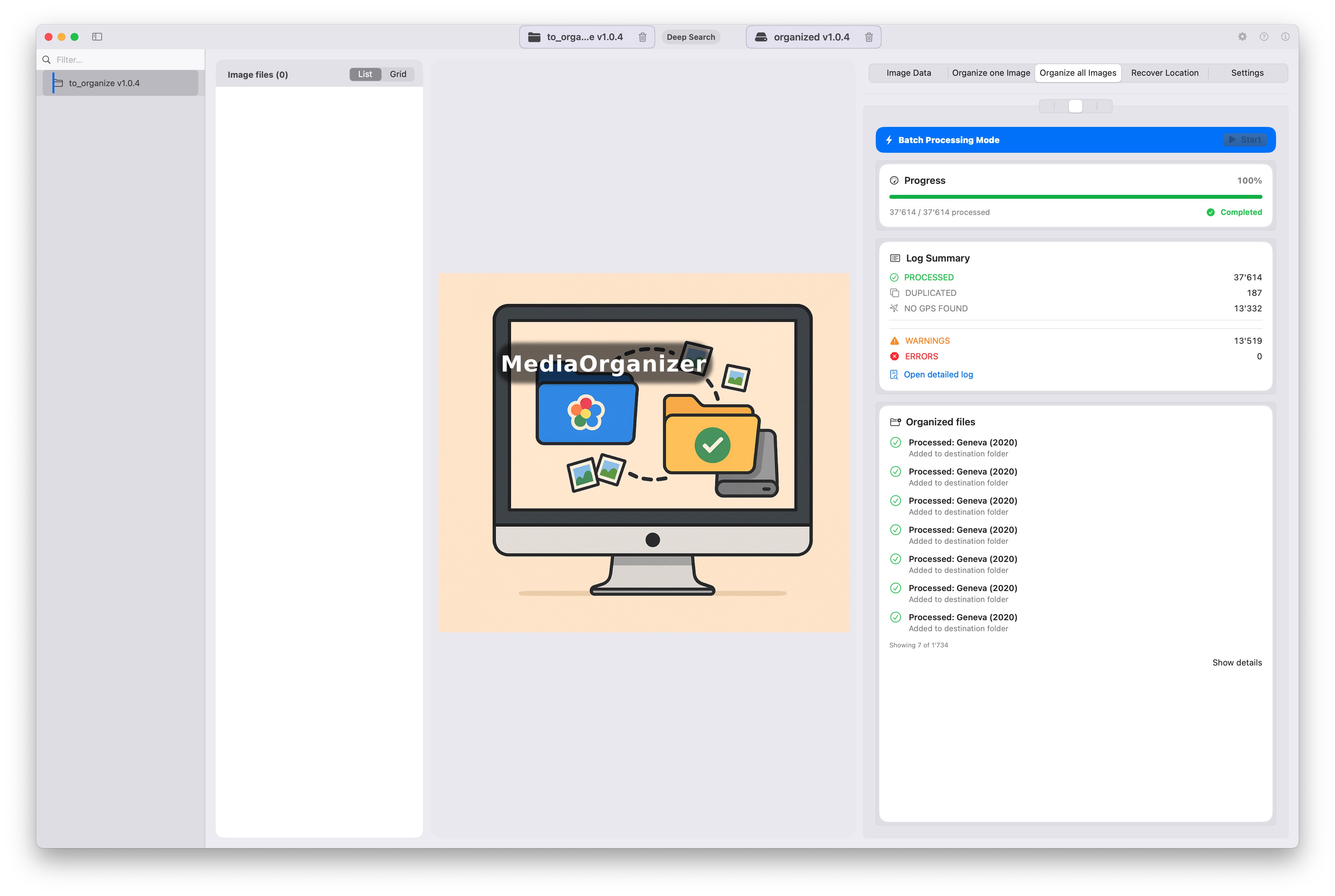
Final run summary:
- Processed: 37,614
- Duplicated: 187
- No GPS: 13,332
- Warnings: 13,519
- Errors: 0
- SQLite cache: 23,306
The most important metric here is not just the number of files processed, but the combination of scale, determinism and zero runtime errors.
What this demonstrates
This run demonstrates that file-level media normalization is not just a conceptual idea. It works on large archives with mixed history, mixed folder logic and long time spans.
- deterministic – files are rebuilt into a stable metadata-based structure.
- scalable – tens of thousands of files can be processed in one workflow.
- catalog-friendly – the resulting archive is easier to feed into Lightroom, Apple Photos or another DAM.
- rebuildable – the archive no longer depends on inherited source folders.
Relationship to media normalization
The results observed in this case study — deterministic structure, stable identity, and controlled handling of duplicates — are direct consequences of applying file-level media normalization as a foundational step before any catalog-based organization.
This confirms that the principles described in the core concept are not theoretical, but operational at scale across large and fragmented archives.
Conclusion
The archive shown here started as a fragmented collection of folders accumulated over nearly two decades.
After normalization, it became a deterministic archive layer that is independent from any single catalog or vendor tool.
That is the role of MediaOrganizer: not to replace catalogs, but to prepare the archive beneath them.
Want the implementation behind this workflow? See MediaOrganizer or start with the core concept page.
![]()